7일 SAC 2023 개최… 한국판 챗GPT ‘루시아’ 공개
환각 현상 대폭 개선… 10월엔 AWS와 협력해 상용화

시사위크=박설민 기자 네이버 ‘하이파클로바X’에 이어 인공지능(AI)·빅데이터 솔루션 전문 기업 솔트룩스가 ‘루시아GPT’를 공개했다. 국내 생성형 AI시장 생태계 확장 및 기술 발전에 큰 보탬이 될 전망이다.
◇1TB 데이터 학습한 루시아GPT, 韓생성형 AI생태계 바꾼다
솔트룩스는 7일 서울 코엑스 3층 오디토리움에서 제 17회 AI컨퍼런스 ‘SAC 2023’을 열고, 루시아GPT와 이를 기반으로 솔트룩스가 그려갈 ‘루시아 생태계’를 전격 공개했다. ‘LUXIA Is All You Need–생성 AI 시대, 모든 것이 달라집니다'’를 주제로 열린 행사에는 AI업계 및 기업 관계자 등 약 3,000여명의 참석자가 방문했다. 온라인 참여자도 2,000여명에 달했다.
이번 행사에서 공개된 루시아GPT는 솔트룩스가 자체 개발한 기업용 거대 언어 모델(LLM)이다. 간단한 질의응답부터 업무 지원, 증강 검색, 문서기반 질의응답, 사용자 맞춤형 답변 등 기업의 업무 효율 향상에 큰 보탬이 될 수 있는 기능들을 대거 탑재했다. 솔트룩스는 자체 개발한 ‘지식추출기술’ 등을 기반으로 약 10년 간 루시아GPT 개발에 매진했다고 한다.
루시아는 AI 데이터 구축 관련 정부 사업뿐 아니라 특허청, 행정안전부 등 다양한 분야의 사업 수행이 가능하다. 데이터 저작권 이슈를 최소화할 뿐 아니라 법률, 특허, 금융, 교육 등 각 전문 분야에 최적화된 맞춤형 언어모델을 빠르고 안전하게 구축할 수 있다는 것이 솔트룩스 측 설명이다.
루시아GPT의 특징은 적은 자원으로 ‘맞춤형 AI서비스’ 이용이 가능하다는 점이다. 이경일 솔트룩스 대표의 설명에 따르면 루시아GPT에 사용되는 파라미터(매개변수)는 70억개, 130억개, 200억개, 500억개다. 솔트룩스는 올해 안에 1000억개 파라미터 규모의 루시아GPT도 준비 중이다.
이처럼 솔트룩스가 루시아GPT의 매개변수를 세분화한 점은 개인, 기업, 연구소 등 다양한 이용자들의 니즈를 맞추기 위함이다. 특히 기업, 연구소에 비해 컴퓨팅 자원이 모자란 개인 이용자의 경우, 비교적 작은 모델인 70억개 파라미터의 루시아GPT를 사용하면 된다. 이는 최신형 그래픽카드 모델인 ‘RTX 4090’ 1대만으로도 구동 가능한 사양이다.
학습된 데이터양도 방대하다. 솔트룩스가 축적해 온 한글 데이터를 약 1TB 이상 학습했다. 이는 약 420만권의 책과 맞먹는 분량이다. 한 사람이 이 데이터를 모두 학습하는데 걸리는 시간으로 환산하면 약 1만2,000년이 걸린다.
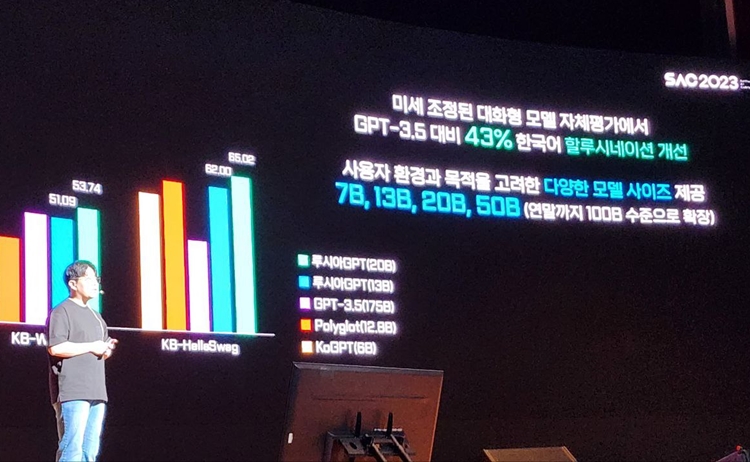
◇ 환각현상 대폭 감소… 한국어에선 GPT-3.5 대비 43%↓
루시아GPT가 갖는 또 다른 장점은 ‘환각 현상(Hallucination)’이 대폭 감소했다는 점이다. 환각 현상이란 챗GPT 등 거대 언어 모델이 거짓 정보를 사실인 것처럼 말하는 현상이다. 이는 AI가 정보를 처리하는 과정에서 발생하는 대표적 오류다. 정확한 정보 제공이 필수인 연구 분야 및 금융권 기업들이 거대 언어 모델 사용을 꺼리는 이유도 이 환각 현상 때문이다.
이 같은 루시아GPT의 강력한 환각 현상 저항력은 솔트룩스 연구진들의 노력 덕분이다. 솔트룩스 개발팀은 AI의 환각 현상을 줄이기 위해 ‘지식그래프(Knowledge Graph)를 활용한 사실/지식 그라운딩(Factual Grounding)’과 ‘검색 증강 생성(RAG·Retrieval-Augmented Generation)’이라는 2가지 접근법을 연계했다.
이때 핵심이 된 기술은 솔트룩스가 자체 연구·개발한 ‘인스트럭트 지식 학습(IKL)’이다. 지식그래프와 연계해 개발된 이 기술은 △인스트럭트 문서 △인스트럭트 개체 관계 △인스트럭트 개체 식별의 3단계로 이뤄진 AI학습방법이다. 1단계에선 개체 이해 능력 강화, 2단계에선 개체 속성값 생성능력 강화가 이뤄진다.
가장 중요한 것은 마지막 3단계 ‘인스트럭트 개체 식별’이다. 이는 여러 문서에 언급되는 개체들의 모호성을 해소하는 역할을 한다. 개체 모호성은 AI 환각 현상의 가장 큰 요인이다. 예를 들어 ‘아이브’라는 아이돌 그룹을 AI에게 물어볼 경우, AI는 애플의 개발자 중 한 명인 아이브로 착각할 수 있는 것이다. 이 문제를 해결하고자 솔트룩스는 자체 개발한 지식추출기술로 정보를 추출한 뒤, AI에게 재학습시켰다.
김재은 솔트룩스 랩장은 “자사 지식그래프와 연계해 자체 연구·개발한 인스트럭트 지식 학습을 통해 오픈AI의 ‘GPT-3.5’ 및 메타의 ‘라마(Llama)2’와 대비했을 때, 한국어 환각 현상 자체 평가에서 약 43% 더 우수한 성능을 확인할 수 있었다”고 설명했다.
솔트룩스는 10월부터 글로벌 빅테크 플랫폼 ‘아마존웹서비스(AWS)’과도 협력해, 루시아GPT 서비스를 상용화할 예정이다. 공개 방법은 사전 학습된 파운데이션 모델을 제공하는 머신러닝 허브 ‘Amazon SageMaker JumpStart’를 통해서다. 솔트룩스는 루시아GPT를 순차적으로 공개, 클라우드 환경에서 고객에게 편의를 제공한다는 목표다.
이경일 솔트룩스 대표는 “솔트룩스를 처음 설립할 때, 세상 모든 사람이 자유롭게 지식 소통하는 세상을 만들겠다는 목표가 있었다”며 “이제 오직 사람을 위한 AI, 사람만을 위한 루시아GPT를 만들고 이를 통해 또 다른 성장을 시작하고자 한다”고 포부를 밝혔다.