내재적·외재적 환각이 대표적… 틀린 데이터 학습으로 오류 발생
네이버·솔트룩스 등 국내 기업, 한국어 모델서 환각 대폭 개선 성공

시사위크=박설민 기자 “푸바오는 대한민국의 유아용 만화 ‘유비 키즈’에서 등장하는 캐릭터입니다. ‘애버랜드(Aeverland)’와는 관련이 없습니다. 푸바오는 애버랜드와는 별개의 만화 작품에서 태어난 판다 캐릭터입니다.”
최근 높은 인기를 구사하고 있는 애버랜드의 판다 ‘푸바오’에 대해 ‘챗GPT’에 물어보자 얻은 답변이다. 일단 가장 기본적인 ‘애버랜드’의 글자부터 틀리고 시작했다. 애버랜드의 영어 스펠링은 ‘Everland’다. 또한 푸바오는 만화에 나온 적도 없다. 애당초 ‘유비 키즈’라는 만화 자체가 존재하지 않는다. ‘2021년 9월로 학습이 멈췄다’는 챗GPT의 변명도 통하지 않는다. 푸바오는 그보다 1년 전인 2020년 7월 20일에 애버랜드에서 태어났다.
이처럼 ‘만능’일 것만 같았던 인공지능(AI)이 실수를 쏟아낸 이유는 ‘환각 현상(할루시네이션, Hallucination)’ 때문이다. 이는 AI가 정보를 처리하는 과정에서 발생하는 대표적 오류다. 챗GPT 등 거대 언어 모델(LLM)의 경우, 거짓 정보를 사실인 것처럼 교묘하게 말한다. AI연구기업들이 가장 골칫거리로 생각하는 문제도 이 환각 현상이다.

◇ 내재적·외재적으로 발생… ‘잘못된 학습’이 주 원인
‘생성형 AI’에서 발생하는 환각 현상에도 여러 종류가 있다. 홍콩 과학기술대학교 인공지능연구센터(CAiRE) 연구진에 따르면 AI 환각 현상은 크게 두 가지로 나뉜다. ‘내재적(Intrinsic) 환각’과 ‘외재적(Extrinsic) 환각’이다.
내재적 환각은 입력된 정보와 생성된 정보가 다른 오류다. 예를 들어 ‘최초의 에볼라 바이러스 백신은 2019년 FDA 승인을 받았다’는 내용을 학습한 AI가 실제 출력한 문장에선 ‘최초의 에볼라 백신은 2021년 승인됐다’고 답하는 것이다. 즉, 아는 내용을 틀리는 것이 내재적 환각이다.
반면 외재적 환각은 입력된 정보와는 전혀 무관한 내용을 출력하는 오류다. 예를 들어 ‘운석 충돌을 막을 수 있는 AI기술이 있는가’라는 질문에 실제론 존재하지 않는 논문 및 연구결과를 제시하는 것이 외재적 환각이다. 앞서 푸바오를 만화 주인공이라 소개한 것 역시 외재적 환각의 예시라 볼 수 있다. 가장 자주 나타나는 환각 유형이며, 치명적 오류가 될 수 있는 현상이기도 하다.
전문가들은 이처럼 AI가 환각 현상을 일으키는 원인은 여러 가지가 있지만, ‘데이터에 의한 환각’과 ‘학습 및 단위에 의해 환각’ 두 가지를 꼽는다. 즉, 사람이 틀린 정보를 학습하면 틀린 답을 내놓는 것처럼, AI도 잘못된 정보를 학습하면 오류가 발생하는 것이다.
김수현 한국과학기술연구원(KIST) 인공지능연구단 책임연구원은 <시사위크>와의 통화에서 “최근 개발된 초거대 AI들은 컴퓨터 파일이나 데이터베이스처럼 정보를 있는 그대로 저장해 두는 것이 아니라 ‘관계성’에 기반해 나름의 지식 체계를 만들어 간다”며 “이 때문에 인간처럼 개념 이해에 장점은 있으나 지식 부문에 있어 항상 정확하게 기억하지는 못한다”고 설명했다.
이어 “AI관련 기업과 연구기관에선 환각을 줄이는 방법은 여러 가지가 시도되고 있다”며 “일반적으론 더 좋은 데이터를 활용하거나 학습 시에 환각 현상을 감소하도록 학습시키기, 모델 구조를 개선하는 방법 등이 있다”고 말했다.

◇ 전문화된 분야일수록 환각 현상 발생 확률↑
환각 현상은 복잡한 인과관계로 얽힌 ‘과학 연구’ 및 ‘금융 분야’에서 발생할 경우, 특히 위험할 수 있다. 데이터 수치 하나만 바뀌어도 결과값이 완전히 달라질 수 있는 분야이기 때문이다. 앞서 소개한 ‘푸바오’의 사례처럼 웃어넘길 수 없는 오류다.
전문지식 분야일수록 환각 현상 발생 확률도 높아진다. 전문가들에 따르면 거대 언어 모델(LLM) 사용시 발생되는 환각은 정밀하게 전문화된 지식분야일수록 5%에서 30%로 증가한다고 하는 것으로 알려졌다.
실제로 지난 1월 국제 의학 전문 학술지 ‘큐리우스(Cureus)’는인 챗GPT를 활용한 의학 논문 작성 콘테스트를 개최했다. 그 결과, 챗GPT는 왜곡된 정보 제공이 심각해, 실제 연구에선 사용 불가능한 것으로 나타났다.
콘테스트에 참가한 인도의 벨가움 의학연구소 연구진은 “AI는 겉보기에 그럴싸한 연구 결과를 인용문으로 제시했는데, 확인 결과 실제론 존재하지 않는 논문이었다”며 “혁신적인 도구임은 분명하지만, 잘못된 정보가 치명적 결과로 이어지는 의료 및 과학 연구 분야에선 사용이 어렵다”고 평가했다.
아울러 세계적인 국제학술지 ‘네이처(Nature)’에서는 지난 6월 생성형 AI를 사용한 사진, 비디오, 일러스트, 그래프 이미지 등의 게재를 금지했다.
금지 이유에 대해 네이처는 “연산, 데이터 분석 등에 AI를 사용하는 것은 허가하지만 생성형 AI를 활용해 얻은 데이터나 이미지 사용은 금지한다”며 “법적 저작권 문제 및 연구 무결성 문제가 발생할 수 있고, 허위 정보 확산을 가속화할 수 있기 때문이다”고 설명했다.
이어 “과학논문 출판과정은 무결성에 대한 공동의 약속에 의해 뒷받침되는 것”이라며 “ 연구자, 편집자 및 발행인으로서 우리는 데이터와 이미지의 출처를 알아야 정확하고, 사실임을 확인할 수 있어야 하는데, 생성형 AI는 이런 검증에 대한 소스를 제공하지 않는다”고 덧붙였다.
이 같은 문제점 때문에 전문가들은 환각 현상이 AI산업 전반을 위협하는 요소로 꼽는다. 한국 딜로이트 그룹은 ‘테크트렌드(Tech Trends) 2023’ 보고서에서 “업무용 애플리케이션이 AI로 진화하게 되면 중요한 것은 ‘AI가 도출한 결과나 상황 측정 모델이 얼마나 정확한가’이다”며 “작업자들은 AI가 제시하는 확률을 100% 신뢰할 수 있어야 하며, 특히 의료 부문 등에서 사용되는 AI의 경우 더욱 중요하다”고 설명했다.
◇ 네이버·솔트룩스 등 국내 기업 환각 현상 대폭 개선
AI의 신뢰성 문제 해결의 중요성이 커짐에 따라, 국내외 AI업계에선 환각 현상 잡기에 총력을 기울이고 있다. 챗GPT 개발사인 오픈AI의 경우, 실수 기반의 ‘강화학습(RLHF)’ 기술로 오류 수정 및 검열을 진행하고 있다. 강화학습은 AI가 반복적 시행착오를 거쳐 작업 수행 방법을 터득하는 머신러닝 기술이다. 학습은 인간 AI트레이너가 챗봇과 나눈 대화를 기반으로 이뤄진다.
국내서도 환각 현상을 대폭 줄인 AI서비스들이 대거 등장하고 있다. 대표적 예로는 네이버의 ‘큐(CUE):’가 있다. 큐:는 네이버가 자체 개발한 초거대AI모델 ‘하이퍼클로바X’를 기반으로 제작된 AI검색엔진이다. 복잡하고 긴 질문을 하이퍼클로바X가 분석한 후, AI가 적합한 검색 결과를 제공해준다. 네이버 내부 테스트 결과, 일반 AI검색엔진 대비 큐:의 환각 현상은 72% 정도 감소한 것으로 알려졌다.
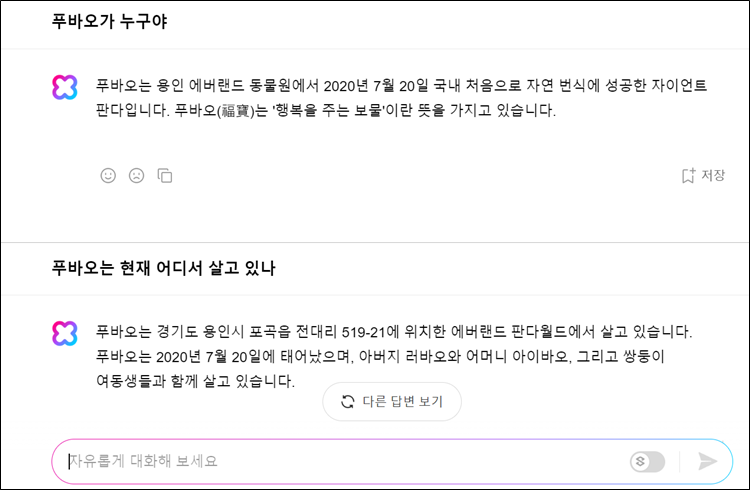
하이퍼클로바X 기반의 대화형 AI서비스 ‘클로바X’도 한국어 질문에 한해선 환각 현상이 개선된 것으로 보인다. 한국어 데이터를 챗GPT 대비 6,500배 이상 학습해서다. 실제로 챗GPT에서 환각 현상이 발생했던 ‘푸바오가 누구야?’라는 질문에 클로바X는 “푸바오는 용인 에버랜드 동물원에서 2020년 7월 20일 국내 처음으로 자연 번식에 성공한 자이언트 판다입니다.”라고 정확히 답했다.

환각 현상 개선에서 주목할 만한 또 다른 기업은 ‘솔트룩스’다. 솔트룩스가 자체 개발한 기업용 거대 언어 모델 ‘루시아GPT’는 챗GPT와 메타의 ‘라마(Llama)2’와 비교해, 한국어 환각 현상이 약 43% 줄었다.
솔트룩스는 루시아GPT의 환각 현상 개선을 위해 AI학습 과정에 ‘인스트럭트 지식 학습(IKL)’ 기법을 적용했다. IKL은 ‘지식그래프(Knowledge Graph: 개체, 사건, 개념 등이 상호 연결된 설명 데이터 모음)’를 기반으로 솔트룩스가 자체 연구·개발한 기술이다. ILK는 △인스트럭트 문서 △인스트럭트 개체 관계 △인스트럭트 개체 식별의 3단계 학습방법으로 구성됐다. 1단계에선 개체 이해 능력 강화, 2단계에선 개체 속성값 생성능력 강화가 이뤄진다.
ILK로 학습한 다음, ‘런타임(AI 동작)’시 발생하는 오류를 줄이는 데는 ‘검색 증강 생성(RAG)’와 ‘지식 그라운딩(KG)’ 기술이 이용됐다. 검색 증강 생성은 AI가 검색된 결과를 보고 배운 다음, 다시 검색해 정답을 찾아가는 과정이다. 지식 그라운딩은 정형화된 데이터를 실시간 연계하고, 답변 생성시 사용할 수 있도록 해주는 기술이다.
정용일 솔트룩스 AIX 본부장은 “솔트룩스는 2013년부터 한국전자통신연구원(ETRI) 총괄로 진행한 ‘엑소브레인’ 과제에서 얻은 아시아 최대 지식그래프와 기술을 얻었다”며 “이 지식그래프의 인스턴스 순은 10억트리프 이상이며, 질문·답 정확도는 98% 이상을 달생했다”고 말했다.
| 2023. 3. 3 | ACM Journals |